DB - 4. Database Design Using the E-R Model
Design Process
Design Phase
DB 디자인은
- Initial Phase : 사용자가 필요할 데이터를 모두 정리
- Second Phase : 데이터 모델을 선정
- 선택한 데이터 모델의 개념을 적용한다.
- 데이터 모델의 요구를 데이터베이스 스키마로 변환한다.
- Final Phase : 추상적인 데이터 모델을 데이터베이스에 적용
- Logical Design : 데이터베이스 스키마 적용
- Physical Design : 데이터베이스의 물리적 구조 결정
의 과정을 거친다.
Design Alternative
DB를 디자인할 때 이 두 가지는 피해야 한다.
- Redundancy : 정보가 중복되면 두 정보가 일치한다는 보장이 없다.
- Incompleteness : 설계가 불완전하면 특정 부분을 모델링하기 어렵거나 불가능하다.
그렇다고 피하기만 해서 끝은 아니고 몇몇 좋은 특성들을 반드시 적용해야 한다.
그중 우리는 Entity Relationship Model이라는 모델과 Normalization Theory라는 개념을 적용할 것이다.
E-R Model
Entity-Relationship Model은 데이터를 엔티티와 엔티티의 관계로 생각하는 모델이다.
현실 세계의 의미와 관계를 DB에 매핑하기 쉽게 표현할 수 있어 자주 사용된다.
ER Model은
- Entity Set
- Relationship Set
- Attribute
로 이루어진다.
그리고, ER Model을 다이어그램으로 표현한 것을 ER Diagram이라고 한다.
Entity Set
Entity는 다른 Object와 구분되는 하나의 Object이다. (학생1, 학생2, 학생3...)
Entity Set은 같은 Property를 가진 Entity의 집합이다. (학생)
(Class와 Instance의 관계와 비슷하다)
Entity는 Attribute의 집합으로 표현 가능하다. (학생1 = (001, Jane, English Dept))
Entity의 Primary Key는 Attribute 집합의 부분집합이다.

ER Diagram에서는 Entity Set을 그림과 같이 표기하고, Primary Key에 밑줄을 긋는다.
Relationship Set
여러 Entity는 Relationship으로 연결되어 있다.
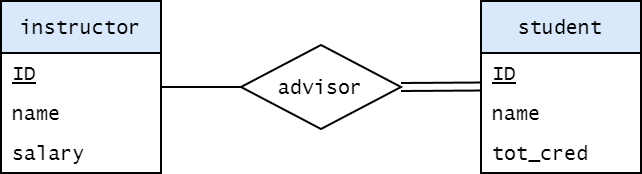
예를 들어, 아래 그림은 Instructor Entity들과 Student Entity들이 Advisor라는 관계로 연결되어 있다고 할 수 있다.

Relationship은 각 Entity의 관계이고, Relationship Set은 Relation의 집합이다.
위 Relationship의 집합을 모으면, Student와 Instructor가 Advisor라는 Relationship Set을 가진다고 일반화할 수 있다.
Relationship Set은 수학적으로 $n \ge 2$인 Entity의 Relation으로 볼 수 있다.
${(e_1, e_2, \ldots, e_n) | e_1 \in E_1, e_2 \in E_2, \ldots, e_n \in E_n}$
ex) $(001, 001) \in advisor$

ER Diagram으로는 이렇게 표현한다.
Relationship Set + Attribute
Attribute 하나와 Entity Set도 Relationship Set을 만들 수 있다.
Instructor와 Student가 만난 Date 정보도 저장한다고 해보자.

이러한 경우 ER Diagram에는 이렇게 표시한다.

Role
같은 Entity끼리도 관계가 있을 수 있다. 이 경우 각 Entity Set은 Relationship에서 Role을 맡는다고 한다.

Degree of Relationship Set
- Binary Relationship : Entity가 두 개인 경우
- Non-binary Relationship : Entity가 3개 이상 (자주 있지는 않음)

Complex Attributes

Attribute도 여러 종류가 있다.
- Simple : 더 분할할 수 없는 Attribute
- Composite : Simple Attribute 여러 개로 이루어진 복합적인 Attribute (주소 = 시 + 동 + 번지)
- Single-valued : Attribute의 값이 하나
- Multivalued : Attribute의 값이 여러 개가 될 수 있음 (취미 : 낚시, 독서...)
- Derived : 다른 Attribute를 통해 얻어지는 Attribute (생년월일 -> 나이)
Mapping Cardinalities
한 Entity와 다른 Entity의 관계에서 얼마나 많은 관계를 맺을 수 있는지를 말한다.
- 일대일

- 일대다

- 다대일

- 다대다

Total / Partial Participation
- Total Participation : 모든 Entity는 이 Relationship에 참여해야한다. (하나라도)
- 두 줄을 그어서 나타낸다.
- Partial Participation : Entity 몇 개는 Relationship에 참여하지 않아도 된다.
- 한 줄로 나타낸다.
Complex Constraints
- Relation의 최대 최소를 선 위에 표시할 수도 있다.

Primary Key
Primary Key로 Entity나 Relation을 구분할 수 있다.
Entity Set
Entity의 정의에 의해 Entity는 항상 구분된다.
데이터베이스의 관점에서 Entity는 Attribute의 차이로 구분되어야 하고, 완전히 같은 값이 있는 Entity는 있어서는 안된다.
이때, 두 Entity를 구분하는 Attribute 집합을 Key라고 한다.
Relationship Set
Relationship Set를 구분하기 위해서 Entity의 Primary Key를 이용한다.
이때 Mapping Cardinality에 따라 Primary Key가 달라진다.
- 일대일 : 둘 중 하나
- 일대다 : Many의 Primary Key
- 다대일 : Many의 Primary Key
- 다대다 : 양쪽의 Primary Key를 모두 사용
Weak Entity Set
ex) 다음과 같은 Course, Section Entity가 있다.
- $course(course\_id, title, credit)$
- $section(course\_id, sec\_id, semester, year, building, room$
section_course Relation을 만든다고 할 때, 이미 section에도 course_id가 있어 section_id는 중복된다. 그러나 이 관계가 course에만 명시되는 것은 바람직하지 않다.
이 경우 course_id를 section에 추가하지 않고, 나머지 특성만 추가해 명시 한 뒤, Weak Entity로 section_course를 course_id를 제공하는 특수한 관계로 만든다.

Weak Entity Set은 다른 Entity에 종속된 Entity를 말한다.
Weak Entity가 아닌 Entity를 Strong Entity라고 한다.
E-R Diagrams to Relational Schema
ER Diagram은 Relational Schema로 나타낼 수 있다.
Strong Entity Set
그대로 만들면 된다.
$$
student(\underline{ID}, name, tot\_cred)
$$
Weak Entity Set
해당 Set을 연결하는 Strong Entity Set의 Primary Key와 합쳐서 표현한다.
$$
section (\underline{course\_id, sec\_id, sem, year})
$$
Attributes
Composite Attributes
Composite Attribute는 앞에 Prefix를 붙여 구분한다.
$$
instructor(ID, name\_first\_name, name\_last\_name, birth\_date)
$$
Derived Attribute
없앤다.
Multivalued Attribute
새 Schema를 만든다.
$$
inst\_phone = (\underline{ID}, \underline{phone\_number})
$$
Relationship Set
Relationship Set도 Schema로 만들어 표현한다.
Mapping Cardinality에 따라 만드는 방법이 다르다.
- 다대다 : 두 Entry Set의 Primary Key를 Attribute로 하는 Schema를 만든다.
$$
advisor = (\underline{s\_id}, \underline{i\_id})
$$
- 일대다, 다대일 : Many가 Total Participation이라면 Schema를 만들지 말고, Many에 One의 Primary Key를 추가한다. 아니면 새 Schema를 생성한다.
$$
instructor(\underline{ID}, name, salary, dept\_name)
$$
instructor-department 관계에서 department의 Primary Key인 dept_name을 instructor에 추가한다.
- 일대일 : 한 쪽을 Many라고 가정하고 처리한다.
Extended E-R Features
Class의 상속과 약간 비슷한 개념이다.
Specialization
Top-Down Design Process로, 상위 레벨 Entity에 Attribute나 Participate를 추가한 하위 레벨 Entity Set을 구성하는 것이다.
ISA라는 이름의 Triangle Component로 표현된다.
Specialize 한두 Entity의 속성을 동시에 사용할 수 있으면 Overlapping, 하나를 선택해야 하면 Disjoint라고 한다.

Specialization을 Schema를 통해 구현하는 방법이 두 가지 있다.
- 하위 레벨에서는 추가 정보와 상위 레벨의 Primary Key만 저장한다.
정보가 중복되지는 않지만, 하위에서 상위의 정보를 가져오려면 Join을 해야 한다.
+----------+------------------+
| schema | attributes |
+----------+------------------+
| person | ID, name |
| student | ID, tot_cred |
| employee | ID, salary |
+----------+------------------+- 하위 레벨에서 상위 레벨 정보를 모두 저장한다.
Join은 안 해도 되지만 정보의 중복이 일어난다.
+----------+-----------------------+
| schema | attributes |
+----------+-----------------------+
| person | ID, name |
| student | ID, name, tot_cred |
| employee | ID, name, salary |
+----------+-----------------------+Generalization
Bottom-up Design Process로 하위 레벨의 공통 분모를 찾아 상위 레벨로 만드는 과정이다. Specialization의 반대 방향이라고 할 수 있다. ER Diagram에서도 똑같이 표시한다.
상위 레벨이 무조건 하위 레벨의 Entity에 속해야 하면 Total, 속하지 않아도 되면 Partial이라고 한다.